Ch 6. Deep Learning¶
Convolutional Neural Networks¶
While MLPs are universal, they struggle with spatially structured data (like images) because they treat pixels as a flat vector, ignoring local topology. Chapter 6 introduces Convolutional Neural Networks (CNNs) and the transition to modern deep learning.
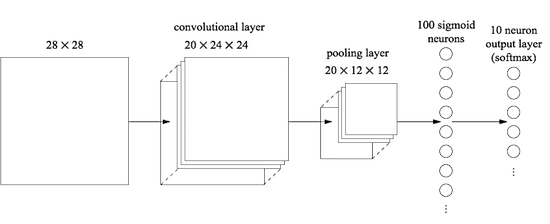
Convolution¶
Instead of connecting every input pixel to every hidden neuron, we connect neurons to small, localized regions of the input. All neurons in a single feature map use the same weights and bias.
It captures local features (edges, corners).
\[
\begin{align*}
a^1 &= \sigma\left(b + \sum_{l=0}^4 \sum_{m=0}^4 w_{l,m} a_{j+l, k+m}^0\right) \\
&= \sigma(b + w \ast a^0).
\end{align*}
\]

Tip
Backpropagation:
\[
\delta_{i,j}^{l-1} = \left( \sum_{m} \sum_{n} \delta_{i-m, j-n}^l \cdot w_{m,n} \right) \sigma'(z_{i,j}^{l-1}), \\
\frac{\partial C}{\partial w_{m,n}} = \sum_{i} \sum_{j} \delta_{i,j}^l \cdot a_{i+m, j+n}^{l-1}, \\
\frac{\partial C}{\partial b} = \sum_{i} \sum_{j} \delta_{i,j}^l.
\]
Pooling¶
Pooling simplifies the information in the output from the convolutional layer.

ReLU¶
Deep networks prefer Rectified Linear Units (ReLU) to Sigmoid:
\[f(z) = \max (0, z)\]
Pros:
- Solves the vanishing gradient problem for \(z > 0\) (gradient is constant 1);
- Much faster to compute than exponentials.
Modern Techniques in Deep Learning¶
- Deep Networks
- Ensemble Learning / Dropout
- Data Augmentation
- ...