Ch 2. Autoregressive Models¶
Representation¶
The fundamental goal is to model the joint distribution \(p(\mathbf{x})\) of \(n\)-dimensional data \(\mathbf{x} \in \{0,1\}^n\).
The Chain Rule Decomposition¶
Using the probability chain rule, any joint distribution can be decomposed into a product of conditionals:
where \(\mathbf{x}_{<i} = [x_1, \dots, x_{i-1}]\).
The Autoregressive Property¶
A model is autoregressive if it respects a fixed ordering of variables. Each variable \(x_i\) depends only on its predecessors.
While a tabular representation of these conditionals leads to exponential space complexity \(O(2^n)\), ARMs use parameterized functions to keep the complexity manageable.
Model Architectures¶
The evolution of ARMs is a journey from simple linear maps to efficient neural weight-sharing.
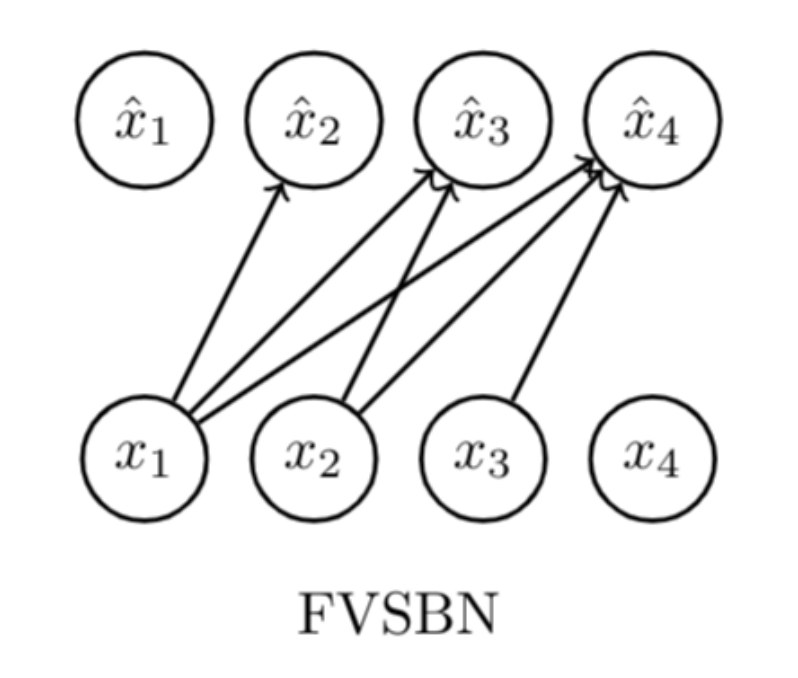
FVSBN (Fully Visible Sigmoid Belief Network)¶
The simplest case where each conditional is a Logistic Regression:
- Complexity: \(O(n^2)\) parameters.
MLP¶
Enhances expressivity by using an independent MLP for each \(i\):
where \(\theta_i = \{\mathbf{A}_i \in \mathbb{R}^{d \times (i-1)}, \mathbf{c}_i \in \mathbb{R}^d, \boldsymbol{\alpha}^{(i)} \in \mathbb{R}^d, b_i \in \mathbb{R}\}\).
- Complexity: \(O(n^2 d)\) parameters, where \(d\) is the hidden layer size.
NADE (Neural Autoregressive Density Estimator)¶
Do weight sharing:
where \(\theta = \{\mathbf{W} \in \mathbb{R}^{d \times n}, \mathbf{c} \in \mathbb{R}^d, \{\boldsymbol{\alpha}^{(i)} \in \mathbb{R}^d\}_{i=1}^n, \{b_i \in \mathbb{R}\}_{i=1}^n\}\).
- Complexity: \(O(nd)\) parameters.
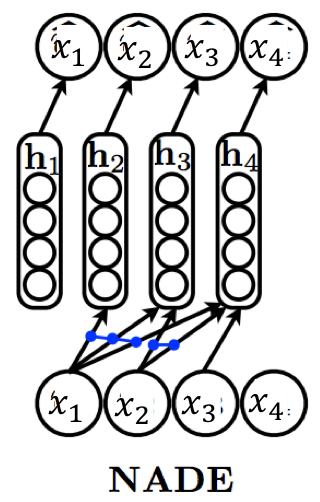
Hidden states can be computed via a recursive update:

RNADE¶
MADE¶
RNN¶
Generative Transformers¶
PixelRNN¶
PixelCNN¶
PixelDefend¶
WaveNet¶
Learning & Inference¶
Maximum Likelihood Estimation (MLE)¶
Learning is framed as minimizing the Forward KL Divergence \(D_{\text{KL}}(p_{\text{data}} \parallel p_{\theta})\):
which is mathematically equivalent to maximizing the Log-Likelihood:
and (if i.i.d.):
Optimization: Solved via Stochastic Gradient Ascent (or Descent on the Negative Log-Likelihood) using Autograd.
Tip
Forward KL Property: "Zero-avoiding," forcing the model to cover all modes of the data (ensuring diversity but potentially causing hallucinated samples).
Inference Tasks¶
- Density Estimation: Parallelizable. We can compute all \(p(x_i | \mathbf{x}_{<i})\) simultaneously if the input \(\mathbf{x}\) is known.
- Sampling: Sequential. Must sample \(x_1\), then \(x_2\) given \(x_1\), and so on. \(O(n)\).